ComfyUI na prática: workflows, usos e diferença para Veo 3 e Gemini
ComfyUI explicado em português — o que é, instalação, usos comuns (ControlNet, LoRA, vídeo) e como se compara a modelos em nuvem como Veo 3 e Gemini Imagem.
Introdução
Se você já usou ChatGPT para texto ou Gemini para editar uma foto, a experiência é familiar: você descreve o que quer e o modelo devolve um resultado. ComfyUI funciona de outro jeito. É uma interface open source baseada em grafos de nós para rodar modelos de difusão — Stable Diffusion, SDXL, Flux, AnimateDiff e dezenas de extensões — no seu hardware ou em uma VM na nuvem. Em vez de um chat, você monta um workflow: caixas conectadas por fios que representam carregamento de modelo, prompt, amostragem, pós-processamento e exportação.
Isso importa porque ComfyUI ocupa um espaço diferente de ferramentas como Google Veo 3 (vídeo generativo na nuvem) ou a geração/edição nativa de imagem do Gemini — apelidada coloquialmente de Nano Banana em tutoriais e fóruns por ser o recurso de imagem integrado ao ecossistema Google. Veo e Gemini entregam mídia a partir de prompt; ComfyUI entrega controle de pipeline. Este artigo explica o que o ComfyUI faz, para que serve na prática, como começar e quando escolher cada abordagem.
Desenvolvimento
O que é o ComfyUI
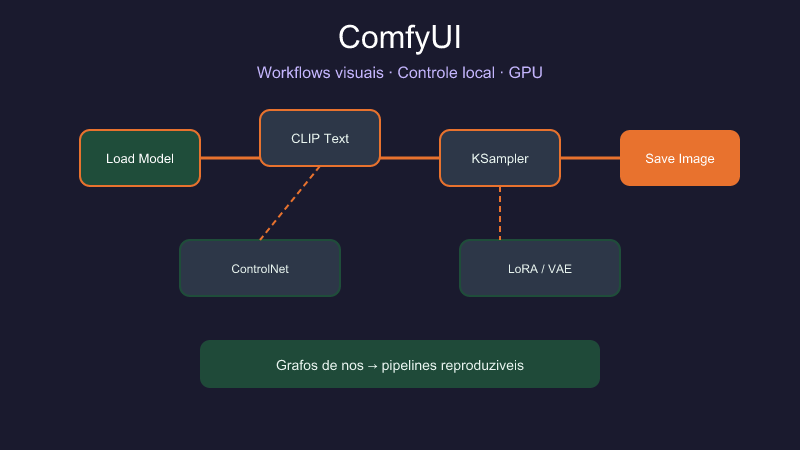
ComfyUI é um frontend node-based para execução de pipelines de difusão. Cada nó é uma operação — carregar checkpoint, codificar prompt com CLIP, aplicar KSampler, decodificar latents com VAE, salvar PNG — e as conexões definem o fluxo de tensores entre eles. O workflow inteiro serializa em JSON; você pode compartilhar, versionar no git e reproduzir pixel a pixel em outra máquina.
O projeto é mantido em github.com/comfyanonymous/ComfyUI. Roda em Python com PyTorch, prioriza eficiência de VRAM (importante em GPUs consumer de 8–12 GB) e suporta filas de geração, histórico e API HTTP para automação. Não é um modelo de linguagem: não conversa. É o motor de orquestração em torno de weights de imagem/vídeo.

Instalação rápida
Requisitos mínimos: GPU NVIDIA com drivers atualizados (CUDA), Python 3.10+ e espaço em disco para checkpoints (modelos base podem ter 2–12 GB cada).
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
python main.py
Abra http://127.0.0.1:8188. Coloque checkpoints em ComfyUI/models/checkpoints/, LoRAs em models/loras/, VAE em models/vae/. A primeira execução baixa dependências conforme o workflow carregado.
Em macOS (Apple Silicon), PyTorch usa MPS; performance varia. Muitos times rodam ComfyUI em RunPod, Vast.ai ou VM própria quando a estação local não tem VRAM suficiente — o software é o mesmo; só muda onde a GPU vive.
Anatomia de um workflow básico
Um grafo mínimo text-to-image contém:
| Nó | Função |
|---|---|
| Load Checkpoint | Carrega SD/SDXL/Flux (UNet + CLIP + VAE) |
| CLIP Text Encode (Prompt) | Positive e negative prompt |
| Empty Latent Image | Define resolução e batch |
| KSampler | Steps, CFG, scheduler, seed |
| VAE Decode | Latent → pixels |
| Save Image | Exporta PNG |
Alterar seed ou CFG e reexecutar só recalcula o necessário — outra vantagem sobre UIs monolíticas. Workflows avançados inserem ControlNet (condicionamento por pose, profundidade, bordas), IP-Adapter (referência visual), Upscale e ramificações paralelas.
Usos mais comuns
1. Geração de imagens (text-to-image)
O caso base: concept art, mockups, variações de produto, thumbnails. Com SDXL ou Flux você controla resolução nativa, aspect ratio e negative prompt para evitar artefatos. Times de marketing usam ComfyUI quando precisam de centenas de variações com seed fixo e metadados embutidos no PNG.
2. Edição e inpainting (img2img)
Carregue uma imagem, aplique máscara e regenere só uma região — trocar fundo, remover objeto, ajustar roupa. O grafo expõe denoise strength: valores baixos preservam composição; altos reinventam a cena. Útil para e-commerce e retoque em lote.
3. ControlNet e consistência estrutural
Quando o prompt sozinho não fixa pose ou layout, ControlNet injeta mapas derivados de entrada (OpenPose, depth, canny). Essencial para personagens recorrentes, storyboards e pipelines onde a geometria importa mais que o estilo textual.
4. LoRA e estilos customizados
LoRAs são adaptadores pequenos (dezenas a centenas de MB) treinados em um estilo, rosto ou produto. No ComfyUI você empilha vários LoRAs com pesos independentes — algo difícil de replicar com precisão em APIs fechadas sem repetir prompt engineering.
5. Vídeo curto (AnimateDiff, SVD, etc.)
Extensões custom nodes adicionam nós de vídeo: clipes de 2–4 segundos a partir de imagem ou texto. Não compete em qualidade cinematográfica com Veo 3 out-of-the-box, mas roda local, sem custo por segundo de API, e combina com ControlNet frame a frame.
6. Upscale e pós-produção
Nós de upscale (Real-ESRGAN, Ultimate SD Upscale tiled) levam 512×512 a 2048+ sem estourar VRAM, processando tiles. Comum no fluxo final de impressão ou assets 4K.
7. Automação e API
ComfyUI expõe API REST/WebSocket. Scripts externos enviam workflow JSON + parâmetros e recebem imagens — base para pipelines internos, integração com CMS ou filas noturnas de render.
ComfyUI vs Veo 3 vs Gemini Imagem (Nano Banana)

A confusão é comum porque tudo gera mídia visual, mas as camadas são diferentes:
| Aspecto | ComfyUI | Google Veo 3 | Gemini (imagem / “Nano Banana”) |
|---|---|---|---|
| Tipo | Orquestrador local de difusão | Modelo de vídeo multimodal (nuvem) | Modelo de imagem/edição integrado ao LLM |
| Entrada | Grafo + weights + parâmetros | Texto, imagem, storyboard (API) | Prompt conversacional ou imagem |
| Saída | PNG, sequências, latents | Clipes de vídeo | Imagem editada ou gerada |
| Controle | Total (steps, CFG, nós) | Limitado aos parâmetros da API | Médio — instrução em linguagem natural |
| Hardware | Sua GPU ou VM alugada | Infra Google | Infra Google |
| Custo | CapEx GPU + energia | Pay-per-use / créditos | Assinatura ou quota API |
| Privacidade | Dados ficam locais | Enviados ao Google | Enviados ao Google |
| Curva | Íngreme (grafos, nodes) | Baixa (prompt) | Baixa (chat) |
Veo 3 é um modelo generativo de vídeo — você pede “câmera lenta de ondas ao pôr do sol” e recebe um clip. Não expõe sampler, não deixa encaixar ControlNet customizado nem trocar UNet por checkpoint open weights. Brilha em prototipagem rápida e qualidade de movimento sem montar infra.
Gemini com geração/edição nativa de imagem (referida como Nano Banana em conteúdos de tutorial por ser o recurso de imagem do ecossistema Gemini/Google AI) funciona como LLM multimodal: você manda texto ou foto e pede “remova o fundo”, “coloque este produto em uma mesa de madeira”. A interface esconde o pipeline; o modelo decide caminhos internos. Excelente para iteração conversacional e usuários que não querem gerenciar VRAM.
ComfyUI é para quem precisa de pipeline reproduzível: mesmo seed, mesmo grafo, mesmo LoRA — amanhã, em outro servidor, no CI. Estúdios, engenheiros de ML e creators avançados usam quando a API fechada não permite o nó que falta ou quando dados sensíveis não podem sair da rede.
Não são excludentes. Fluxo híbrido comum: rascunho no Gemini → export PNG → inpaint/refino no ComfyUI → upscale final. Ou storyboard no Veo → frame-chave no ComfyUI com ControlNet para consistência de personagem.
Exemplo de workflow mínimo (conceito)
Salvar como workflows/txt2img_basico.json após montar na UI (File → Save) ou usar o template default. Parâmetros típicos para SDXL:
# Referência de parâmetros — ajuste no nó KSampler na UI
steps: 28
cfg: 7.0
sampler_name: euler
scheduler: normal
denoise: 1.0
width: 1024
height: 1024
seed: 42
Prompt positivo exemplo:
retrato editorial, iluminação suave, fundo verde musgo,
fotografia 85mm, pele natural, alta qualidade
Negativo:
borrado, baixa resolução, texto, watermark, membros extras
Para batch de 10 variações, duplique o nó latent batch ou use queue (Ctrl+Enter enfileira; Ctrl+Shift+Enter executa imediato).
Custom nodes e ecossistema
ComfyUI cresce via ComfyUI-Manager e repositórios community. Instale Manager clonando em custom_nodes/, reinicie, busque pacotes (ControlNet aux, Impact Pack, Video Helper Suite). Cuidado: nodes de terceiros quebram entre versões — fixe versão do ComfyUI em projetos de produção.
Estrutura útil:
ComfyUI/
├── models/checkpoints/ # .safetensors principais
├── models/loras/
├── models/controlnet/
├── custom_nodes/ # extensões
├── input/ # imagens para img2img
└── output/ # PNG gerados
Quando escolher ComfyUI
Escolha ComfyUI se:
- Precisa de controle fino e workflows versionáveis
- Trabalha com LoRA, ControlNet ou modelos open weights
- Volume alto de geração onde API cloud ficaria cara
- Privacidade ou compliance exige processamento local
- Quer integrar geração de imagem em pipeline automatizado
Prefira Veo 3 ou Gemini se:
- Prioridade é time-to-first-pixel sem configurar CUDA
- Equipe não tem GPU nem appetite para manter VM
- Tarefa pontual de vídeo ou edição conversacional
- Qualidade out-of-the-box basta sem tunar sampler
Limitações honestas
ComfyUI exige manutenção: drivers, PyTorch, conflitos de custom nodes, downloads de dezenas de GB de models. Debugging é olhar o grafo e logs — não há chat que “conserta” o resultado. Vídeo longo e áudio sincronizado ainda ficam atrás de stacks comerciais. Para iniciantes, começar no Gemini e migrar trechos para ComfyUI quando bater no teto de controle costuma ser menos frustrante do que abrir um grafo vazio no dia one.
Conclusão
ComfyUI não compete head-to-head com Veo 3 ou Gemini Imagem — resolve outro problema. Veo e Gemini são modelos multimodais em nuvem acessados por linguagem natural; ComfyUI é bancada de montagem para difusão open weights, com transparência total do pipeline. Os usos mais comuns — text-to-image, inpainting, ControlNet, LoRA, upscale e batches via API — aparecem quando você precisa repetir, escalar e auditar o processo criativo.
Próximo passo prático: clone o repositório, rode o workflow default, gere dez imagens variando seed e compare com o mesmo prompt no Gemini. A diferença de controle fica óbvia em minutos.
Referências